Overview
A number of Tier2-centric data services need to be operational in order to efficiently use the cluster, network, and storage resources of a Tier2 center, and to provide optimal access to (primarily) AOD, ESD and TAG datasets for ATLAS physcists. Initial focus is on development of a
Data Skimming Service which uses metadata and TAG database queries to efficiently process Tier2-based AOD processing tasks.
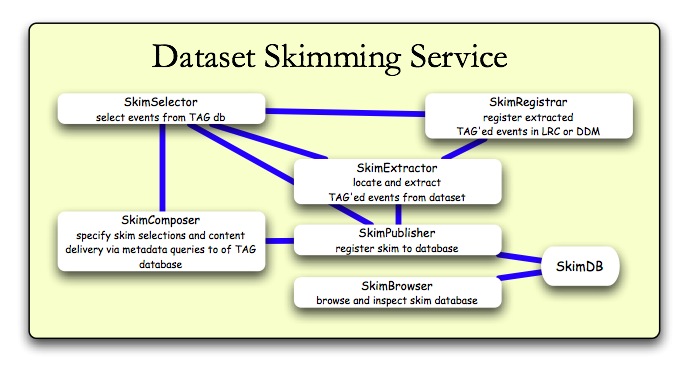
Description
Deliver a service to provide simple and efficient access to, and event extraction from, datasets locally resident at Tier2 centers. Considerations:
- A Tier2 center will have a full replica of all ATLAS AOD datasets, according to the Computing TDR.
- Focus on the most common use cases for data skimming
- Do these simple, standard tasks more efficiently and easily than what a physicist would need to do himself.
- Articulate these use cases. For example:
- Tell me what datasets are available at the Tier2 (eg. using DDM browser). Add analysis checks:
- I the dataset complete?
- Are they accessible - fileservers working?
- Is the catalog contents consisent with disk?
- Tell me the content and format (containers, POOL format, etc).
- Give me all events subject to (
cut set 1, cut set 2), saving only the (jets, electrons) objects in the output file.
- Put those files into the Tier2
output buffer, easily accessible to local, Tier3, etc.
- Let me know when its complete, and if there were any errors. Also, how long I have to get them before the space is reclaimed.
- Provide this initially as a local service
- Focus on simplicity of design and operation.
- Avoid grid services, at least initially, but use various backends if available (eg. Pathena for distributed skimming).
- Avoid remote, centralized services, systems and catalogs where possible.
More discussion points available here:
DssDisccusion.
Software Components
Tier2 infrastructure and services
Project plan
The project fits into the US ATLAS project plan in the Data Services section of the Facilities plan (WBS 2.3.4).
Meeting notes and action items
Tier2 Database Infrastructure
What are the Tier2 activities associated with providing the appropriate ATLAS database infrastructure necessary for Monte Carlo production and AOD analysis?
Discussions from the Tier2 Workshop
General agreement that it was necessary to provide Tier2 centers with a recipe for building/providing the necessary database infrastructure, including Mysql database services, Squid caches, etc.
Tag and Event Store
Conditions and Tag databases
Action items:
- Test database services for Condition and Tag databases
- Start with the current model for deployment and access
- Develop requirements based on use cases
- Provide a deployment recipe (Pacman-based) and documentation.
Calibration and Alignment Challenge
Check the readiness for the Calibration Alignment challenge (CAC will be this fall, after Release 13, at the end of September). This must be done for all Tier2 centers, and should use the results of prototyping activities.
- Provide a database service (one machine with DB server hosting Tag and Conditions DB - will be finalized by prototyping):
- Tag: probably a single dedicated mysql server.
- Conditions: probably file based database like SQLlite, but may be mysql.
- Access to these services will be local, from within the Tier2 site.
- Have at least one static replica of the whatever Calibration and Conditions are needed for the challenge (less than 1 TB).
- Be prepared to have one dedicated server with a 1 TB of space.
Other groups working to similar projects:
- Glasgow: Caitriana Nicholson and Helen Mc Glone: working on the ATLAS tag database, and in particular at the moment looking at how to integrate the tag database with the Distributed Data Management (DDM) system, DQ2.
DataServices Web Utilities
--
MarcoMambelli - 25 May 2006
--
RobGardner - 07 Aug 2006


{kind=link}
{kind=link}
{kind=link}
{kind=link}