|
|
You are here: Foswiki>DataServices Web>SkimSelector (23 May 2007, JerryGieraltowski)Edit Attach
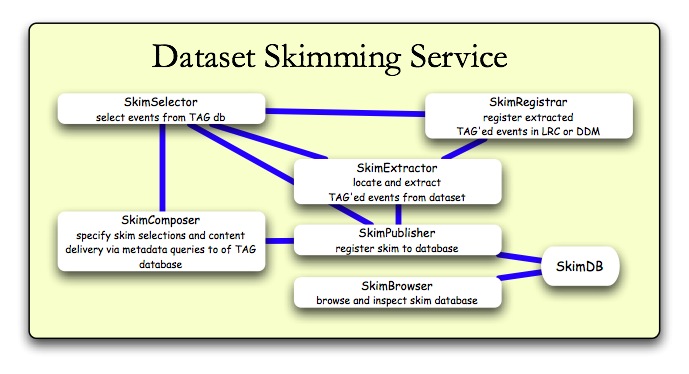
SkimSelector
Developers
Jerry, MarcoInputs
- full path to a configuration file identifying all job variables needed in the workflow of both skimSelector and skimExtractor
Outputs
The skimSelector generates one or more "root" collection files and associated PoolFileCatalog.xml files. These files as well as a "canned" event extractor "jobOptions" file (called EventExtractor.py) are made available to the skimExtractor script. The skimSelector calls the skimExtractor and subsequently returns directly to the skimComposer.Task Description
Extracts events references from TAG database based on metadata queries and store them in root-based collections. A utility to do this exists in PoolCollectionTools: CollSplitByGUID.exe. This can either create a single file, a file per GUID, or files with some minimum number of events.- The output names and locations can be stored in the Skim Data Service bookkeeping, i.e. Publisher. In addition the following things could occur.
- These files can be used directly as input to the Skim Extractor.
- These files can be imported back into the TAG database and labelled appropriately. The selection criteria, i.e. the output of the SkimComposer and input to SkimSelector, should also be stored,.
- These files may be registered in the DDM as a new dataset.
External Dependencies
- A functional TAG database
- A DSS configuration file specifying all of the variables needed by the DSS services
- An installed ATLAS Release specific to the Release identified in the input configuration file
- An installed globus installation (either VDT or OSG installation)
Current Implementation
The current implementation of the skimSelector is the executable script "skimSelector.sh". skimSelector requires an input variable specifying the full path to a DSS configuration file>skimSelector.sh full_path_to_DSS_configuration_fileThe assumption being made is that the DSS configuration file (referenced as DSS.conf in subsequent sections) has been previously created by the skimComposer. The following actions are performed by the skimSelector before handing off the workflow to the skimExtractor.
- source the configuration file DSS.conf
- create a job directory to store all job related files and outputs
- create a logFile in the job directory
- copy the following files to the job directory: EventExtractor.py (the jobOptions file for event extraction), the Pool Utilities: CollSplitByGUID.exe, CollListFileGUID.exe, and the script to create PoolFileCatalog.xml files - createPoolFileCatalog.sh
- source the setup script for the appropriate ATLAS Release stored on the DSS server. The ATLAS Release number is specified in DSS.conf
- execute a skim selection on the identified TAG database for the selected "skim query"
- check that an output root collection file was created. If so, pass the workflow on to skimExtractor. If not, return with an error condition to skimBrowser.
###################################################################
# File: DSS.conf
# Description: Job configuration file needed
# by the DSS services when
# executing a user job
# NOTE: This sample configuration file is specific to
# dss_submit_server: tier2-06.uchicago.edu
# target_grid_site: uct2-grid6.uchicago.edu
###################################################################
#
#==================================================================
#PART 1: DSS_SUBMIT_SERVER specific variables
#Location of ATLAS application on DSS server
export DSS_ATLAS_APP=/share/app/atlas_app
#ATLAS Release Number
export DSS_ATLAS_REL=12.0.5
# Configuration file with user parameters for TNT
export LFC_HOST=''
# --- which grid to use (and any related parameters) ---
# should be one of LCG, OSG or NG
export GRID_TYPE=OSG
# path to jobs directory (The directory in which all submitted jobs will be stored).
export DSS_jobdir=$HOME/DSSjobs
#
#==================================================================
#PART 2: TARGET_GRID_SITE specific variables
#Condor universe and job scheduler
# values for local condor
#export DSS_UNIVERSE=vanilla
#export DSS_TARGET=''
#export DSS_TARGET_NAME=`hostname`
#export DSS_MASTER="dssmaster.sh"
#export DSS_PILOT="dsspilot.sh"
#values for external grid site
export DSS_UNIVERSE=globus
export DSS_TARGET="uct2-grid6.uchicago.edu/jobmanager-pbs"
export DSS_TARGET_NAME=MWT2_UC
export DSS_MASTER="dssmaster.sh"
export DSS_PILOT="dsspilot.sh"
#Location of d-cache utilities on execution site
export DCACHEDIR=/opt/d-cache
#Location of ATLAS application on remote server
export ATLAS_APP=/osg/app/atlas_app
#Location of WN_CLIENT installation (visible VDT installation)
export OSG_WN_CLIENT=/opt/OSG
#place where COMMON files are stored, accessible from the WN
export DSS_STORE=/share/data/t2data/
#place to store output results
export DSS_RESULTS=${DSS_STORE}/results
#==================================================================
#
#==================================================================
#PART 3: TAG_DATABASE specific variables
# --- Arguments for POOL Collection Utilities ---
export SRC_COLLECTION_NAME="trig1_misal1_csc11_005403_TAG_v12000601"
export SRC_COLLECTION_TYPE="MySQLltCollection"
export SRC_CONNECTION_STRING="mysql://tagreader@tier2-06.uchicago.edu/tier2tagdb"
#==================================================================
#
#==================================================================
#PART 4: DQ2_LRC specific variables
#location of DQ2 LRC Catalog
export DQ2_CATALOG="http://uct2-grid1.uchicago.edu:8000/dq2/lrc"
#URL of PFN targets in PoolFileCatalog.xml file
export DSS_POOLFILECATALOGTARGET="uct2-dc1.uchicago.edu"
#==================================================================
#
#==================================================================
#PART 5: USER_JOB specific variables
# query to be run on database: DO NOT include quotation marks
export QUERY="NJet>0&&NLooseElectron>0"
# items for input sandbox (other than pre-defined defaults)
export INPUT_SANDBOX=EventExtractor.py
# items for output sandbox (other than pre-defined defaults)
export OUTPUT_SANDBOX=
# --- whether to register output in DQ2, and related parameters ---
export REGISTER_OUTPUT=no
# name of output file(s) to be registered on grid
# if > 1 output file, use a space-separated list for the files
export OUTPUT_FILES=''
export OUTPUT_DATASET_NAME=''
export OUTPUT_DATASET_LOCATION=''
# set the minimum number of events per collection
export DSS_minevents=1000
# set the number of events to skip
export numEvts2Skip=25
# set the number of events to process
export numEvts2Process=1500
#==================================================================
Questions/Comments
-- JerryGieraltowski - 23 May 2007 -- MarcoMambelli - 14 Nov 2006 -- RobGardner - 06 Nov 2006

| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
dss-v2.jpg | manage | 66 K | 15 Nov 2006 - 21:48 | RobGardner | v2 |
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r8 < r7 < r6 < r5 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r8 - 23 May 2007, JerryGieraltowski
Ideas, requests, problems regarding Foswiki? Send feedback